Алертинг в Proto Observability Platform
Правила алертинга, доступные сразу после установки Proto OBP
Из коробки доступно множество шаблонов правил алертинга не требующих никакой дополнительной настройки.
Список правил доступен в разделе Алерты > Правила:

Встроенные правила алертинга не редактируются пользователями системы, но их можно отключить или сделать копию встроенного правила, и уже в копии правила отредактировать все параметры правила.
Встроенные правила алертинга периодически обновляются и добавляются вендором.
Добавление собственных правил алертинга
Для добавления собственных правил алертинга воспользуйтесь кнопкой Добавить в разделе Алерты > Правила:

Proto Observability Platform поддерживает выражения в правилах алертинга, написанные на языках PromQL и MetricsQL.
После изменения, отключения или добавления правил необходимо нажать на кнопку Применить для применения изменений – новые настройки правил применятся в течение 1 минуты.
Использование метрик для создания правил
Список всех доступных метрик можно посмотреть в режиме создания графика: Дашборды > + Дашборд > выбрать название для дашборда > Добавить виджет > выбрать тип графика PromQL > выбрать тип визуализации (например, линейная диаграмма), далее поле PromQL запрос поместите курсор, и вы увидите список доступных метрик:

Для сервисов доступны следующие ключевые метрики для создания правил алертинга:
service_apdex: значение APDEX для сервиса, диапазон значений от0до10 000(10 000соответствуетAPDEX = 1на графиках);service_calls_sum: сумма всех вызовов сервиса;service_cpm: количество вызовов сервиса в минуту (calls per minute);service_error: процент ошибок сервиса;service_error_sum: диапазон значений от0до10 000(100 000соответствует100%ошибок);service_resp_time: время отклика сервиса, в миллисекундах;service_sla: диапазон значений от0до10 000(10 000соответствуетSLA = 100на графиках);
Для сервисов доступны следующие лейблы метрик:
service: имя сервиса, анологичное отображаемому имени сервиса в разделеПриложения>Сервисы.service_id: внутренний идентификатор сервиса для генерации ссылки на дашборд (смотри добавления аннотации ниже)
Для применения в правилах фильтра по конкретному сервису, используйте синтаксис:
-
метрика{лейбл="значение"}, например для метрикиservice_resp_timeи сервисаpayment_bankможно использовать такое выражение:-
service_resp_time{service="payment_bank"}(среднее значение времени исполнения сервисаpayment_bankв миллисекундах), пример выражения для правила:avg(service_resp_time{service="payment_bank"}) by (service, service_id) > 100
-
Правила создаются в веб-интерфейсе, описание возможных полей:
# Имя правила. Должно быть валидным именем метрики.
alert: <string>
# Выражение PromQL/MetricsQL для анализа
expr: <string>
# Правило считается сработавшими (firing), если оно выполняется указанное время.
# Правила, для которых критерии выполняются, но заданное время не прошло, имеют статус pending.
# Если параметр опущен или установлено значение 0 - правило будет срабатывать сразу же.
[ for: <duration> | default = 0s ]
# Правило будет в статусе сработавшего указанный интервал времени, даже после того как выражение не будет возвращать результат
[ keep_firing_for: <duration> | default = 0s ]
# Лейблы, которые будут добавлены к каждому алерту.
labels:
[ <labelname>: <tmpl_string> ]
# Аннотации, которые будут дообавлены к каждому алерту.
annotations:
[ <labelname>: <tmpl_string> ]
Пример создания правила:

Выражение (время отклика сервиса payment_bank больше 100 мс):
avg(service_resp_time{service="payment_bank"}) by (service, service_id) > 100
service_resp_time– метрика: время отклика сервиса;{service="payment_bank"}– фильтр по имени сервисаavg(service_resp_time{service="payment_bank"}) by (service, service_id) > 100– аггрегация по имени сервиса и лейблуservice_id(для использования лейблаservice_idв аннотациях для получения ссылки на дашборд сервиса)
Добавление аннотаций и лейблов:
-
аннотации позволяют добавлять дополнительные метки к алертам, аннотации приходят в уведомления (Email, Telegram, Webhook и тд)
-
лейблы позволяют группировать алерты и используются в политиках маршрутизации алертов.
-
зарезервированные ключи (имена) аннотаций:
dashboard,dashboardService– ссылка на дашборд сервиса в веб-интерфейсе Proto OBP, для добавления используйте следующее значение:{{ $externalURL }}/dashboard/GENERAL/Service/{{ .Labels.service_id | reReplaceAll "__" "==" | reReplaceAll "_" "=" }}/Proto-General-ServicedashboardHost– ссылка на дашборд сервера в веб-интерфейсе Proto OBP, для добавления используйте следующее значение:{{ $externalURL }}/dashboard/OS_LINUX/Service/{{ .Labels.service_id_host }}/Proto-Linux-ServicedashboardContainer– ссылка на дашборд контейнера в веб-интерфейсе Proto OBP, для добавления используйте следующее значение:{{ $externalURL }}/dashboard/OS_LINUX/Endpoint/{{ .Labels.service_id_host }}/{{ .Labels.service_id_host }}_{{ .Labels.service_id_container }}/Proto-Linux-Docker
Примеры использования аннотаций – ссылок на дашборды:
-
Telegram уведомления:

-
Веб-интерфейс Proto OBP:

Автоматическое выявление аномалий
В Proto Observability Platfrom используются механизмы машинного обучения (ML) для автоматического построения базовой линии (трендов, baseline) по трем ключевым показателям производительности для каждого приложения:
- количество транзакций в минуту (
service_cpm) - процент ошибок (
service_cpm) - время исполнения

Тренды строятся с учетом сезонности показателей – недельной и дневной.
Из коробки в Proto OBP доступны правила алертинга на основе базовой линии:

Интеграция с CI/CD
Вы можете сообщать в Proto Observability Platform информацию о сделанном релизе из вашего CI/CD пайплайна. Для этого встройте в свой пайплайн вызов скрипта marker.sh со следующеми аргументами:
./marker.sh "адрес_бекенд_сервер" "название_релиза" "название сервиса (опционально)"
- Адрес бэкенд сервера указывается без префикса
https:// - Название релиза – короткая строка, например, номер коммита, версия релиза и тд.
- Название сервиса:
- если указано – маркер релиза будет отображаться только у этого конкретного сервиса.
- если не указано – маркер релиза будет отображаться у каждого сервиса (то есть релиз распространяется на все сервисы).
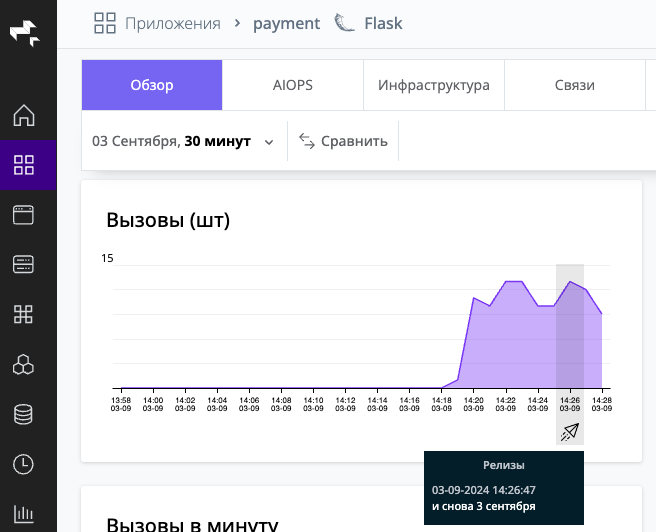
Например:
./marker.sh "proto-backend.fqdn" "и снова 3 сентября"
Содержимое marker.sh:
#!/bin/bash
PROTO_BACKEND_URL=${1}
PROTO_RELEASE_NAME=${2}
PROTO_SERVICE_NAME="${3}"
generate_post_data()
{
now=$(date +%s000)
if [ -z "${PROTO_SERVICE_NAME}" ]; then
cat <<EOF
[
{
"uuid": "${now}",
"name": "${PROTO_RELEASE_NAME}",
"source": {
"service": ""
},
"layer":"GENERAL",
"type": "RELEASE",
"message": "Релиз: ${PROTO_RELEASE_NAME} Сервис: Все",
"parameters": {},
"startTime": ${now},
"endTime": ${now}
}
]
EOF
else
cat <<EOF
[
{
"uuid": "${now}",
"name": "${PROTO_RELEASE_NAME}",
"source": {
"service": "${PROTO_SERVICE_NAME}"
},
"layer":"GENERAL",
"type": "RELEASE",
"message": "Релиз: ${PROTO_RELEASE_NAME}",
"parameters": {},
"startTime": ${now},
"endTime": ${now}
}
]
EOF
fi
}
# echo $(generate_post_data) | jq
curl -i -k \
-H "Accept: application/json" \
-H "Content-Type:application/json" \
-X POST --data "$(generate_post_data)" "https://${PROTO_BACKEND_URL}/v3/events"